Runtime
-
- I have to specify followlocation = TRUE for all my requests. Why can't RCurl just do this for me.
- The reason RCurl doesn't set default values for Curl options is because it might be confusing. Instead, we leave it to the R user/programmer to explicitly set any of the options she wants. This can be repetitive. To avoid this repetition, we allow the R user to specify the R option named "RCurlOptions". This is consulted in each request (or specifically when we create a new curl handle) and merged with the values specified explicitly in the call.
options(RCurlOptions = list(verbose = TRUE, followlocation = TRUE, timeout = 100, useragent = "myApp in R")) v = getURLContent("http://www.omegahat.org")With this, we can see that our useragent appears in the HTTP header of the request. We see this since the verbose = TRUE shows the header of the request and the response.- Why doesn't RCurl provide a default value for the useragent that some sites require?
- This is a matter of philosophy. Firstly, libcurl doesn't specify a default value and it is a framework for others to build applications. Similarly, RCurl is a general framework for R programmers to create applications to make "Web" requests. Accordingly, we don't set the user agent either. We expect the R programmer to do this. R programmers using RCurl in an R package to make requests to a site should use the package name (and also the version of R) as the user agent and specify this in all requests.
Basically, we expect others to specify a meaningful value for useragent so that they identify themselves correctly.
Note that users (not recommended for programmers) can set the R option named RCurlOptions via R's option() function. The value should be a list of named curl options. This is used in each RCurl request merging these values with those specified in the call. This allows one to provide default values.
- I try to retrieve a page, but getURLContent() and getURL() both just hang. I have to kill the R session. What is the problem? What can I do?
- First thing to do is to check whether this a problem on the server. You can do this by loading the URL in a Web browser or via a command-line tool such as curl or wget. If this does not succeed, then the problem is most likely with the server.
There are a couple of things that come to mind. Firstly, specify a value for the curl option "useragent" and give it something meaningful to identify your application. Hopefully adding that resolves the problem. It does in the case
getURLContent("https://mtgox.com/code/data/ticker.php", ssl.verifypeer = FALSE, useragent = "R")If that doesn't solve the problem, set a value for the "timeout" option.
getURLContent("https://mtgox.com/code/data/ticker.php", timeout = 4, ssl.verifypeer = FALSE)This will at least cure the "hanging" indefinitely and return within that period of time.- When I go to a page that is just a directory, I get results about "302 Moved Permanently". My browser shows the list of files. What's the difference?
- Not entirely certain yet! But try putting a / at the end of the URI, e.g. change
http://www.omegahat.org/RCurltohttp://www.omegahat.org/RCurl/That works for me.- Why does https not work for me?
- Probably because when you compiled/installed libcurl, you didn't have support for SSL. You can check this with the command
curl-config --feature
If ssl doesn't appear there, you don't have support for it. You should reinstall curl, having first installed SSL (e.g. openssl).- I'm trying to use RCurl to do something in R that works in a Web browser and I can even reproduce using the command line program curl. (That's a big help as we know we are both using libcurl!) But when I do things in R, it fails. What's the problem and how can I fix it?
- Well, there are too many potential reasons and we would need to have more information about what you are attempting to do and what the error messages are. But for one, you might look at authentication and activating Basic authentication, e.g add
httpauth = 1L, # "basic"to the curl options.But there is a general approach to trying to figure out how to get R to do the same thing as a browser or curl or wget. One approach is to make certain that both R and curl are giving us as much information as possible. So make sure both have verbose switched on. In R, this is a curl option
verbose = TRUEand for curl, is is the command line switch -v. Then look at the header information both produce and see if anything is obviously missing or different in the R version.A different idea is somewhat advanced, but not very. When the browser or curl makes a request, it is sent across the network via your operating system. What we want to do is look at the contents of the HTTP request and specifically the header information. There are two ways to do this. If we are doing this in a browser, we can examine the headers in that browser using browser-specific tools. Alternatively, if we are doing this via a command line utility or if we want to do this generally, we can capture all the network communication using a tool such as tcpdump or wireshark.
If we want to do this via the browser, we can use the LiveHTTPHeaders extension for Firefox or the "special" URL chrome://net-internals for Google Chrome.
For command-line/stand-alone tools, with the appropriate permissions on the computer, we can use a program such as tcpdump or wireshark or ethereal to "sniff" or capture the packets as they go across the network device and then we can look at them. We can do this for the curl or browser and then for R and compare what is being sent. This allows us to see the headers as we can with the verbose options, but it also allows us to see the content of the body of the request. This is only important for POST requests.
We should also note that if you are using HTTPS, the body will be encrypted and you won't be able to make any sense of it. However, if the data in the post are not sensitive, you can send it via HTTP - not HTTPS - and curl and the Web browser will do the same thing and we will be able to see the contents. The server will likely be confused and upset and give an error, but we are trying to determine the problem on the initial client request so that is not a problem. (It is a problem if we are trying to understand why R is not handling the response correctly, but that's a different problem.)
How do we use tcpdump and ethereal? First, start tcpdump just before you run the R or curl command
sudo /usr/sbin/tcpdump -s 1518 -i eth1 -w r_packets.tcp
If you do this and wait too long, you will capture all the background packets that are flying through your network interface that have nothing to do with your problem. This is not a problem, but it makes it harder to find the packets which we want to examine.So next, go back to R or curl and run the command. When this has completed, kill the tcpdump process, e.g Ctrl-C in the terminal in which it is running or kill with the relevant process id (see the ps command or the Mac activity monoitor.) Now run ethereal with the name of the file to which tcpdump serialized the packets
ethereal r_packets.tcp
And then you will get a window that looks something like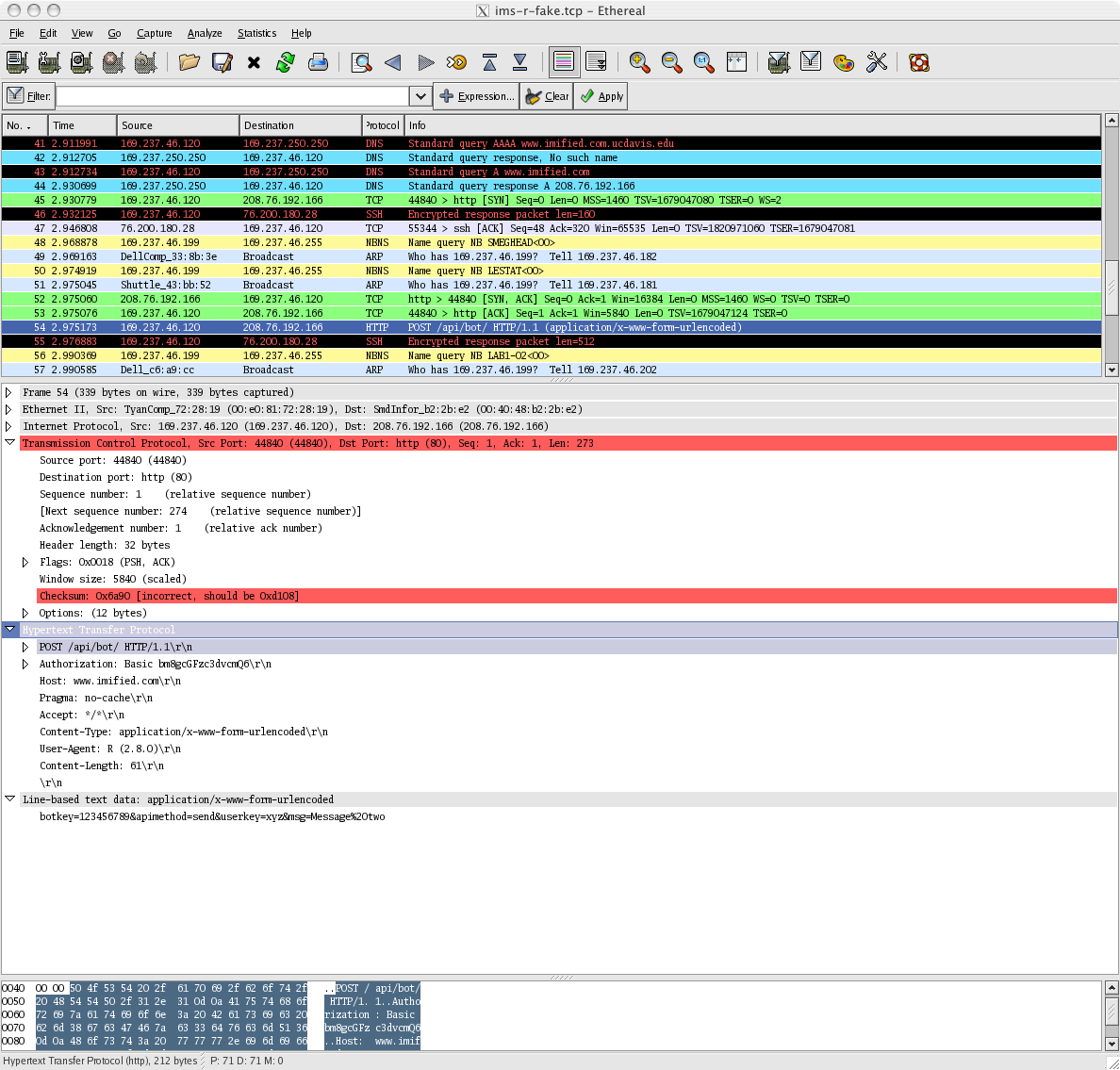 You navigate the list in the top panel to find the HTTP
entry (#64 in our example).
Click on that and the details of this TCP interaction are displayed
in the lower panel. Then you can expand the elements by clicking
on the lines that have an arrow on the left.
And then you'll see the details of the header and the body.
You navigate the list in the top panel to find the HTTP
entry (#64 in our example).
Click on that and the details of this TCP interaction are displayed
in the lower panel. Then you can expand the elements by clicking
on the lines that have an arrow on the left.
And then you'll see the details of the header and the body.
If the connection is via SSL, e.g. HTTPS, things are a little more complicated as the content is encrypted. There are a variety of ways and tools to deal with this. Some are (in no particular order)
- ssldump
- Burp
- Paros Proxy
- fiddler (Windows)
- WebScarab (Java)
- Charles (commercial)
- HttpWatch (Windows only, Free and commercial)
- I am trying to use the
verbose = TRUEoption in curlPerform() or some of the other higher-level functions, but there is no output appearing on the console. What's the problem?- You're on Windows using the R GUI, aren't you? If so, chose the option in one of the menus that controls whether output is buffered and unselect it, i.e. so the output is not buffered. That should do it.
- I can't use scp or sftp within RCurl but the documentation for curl seems to suggest that it can. So why does RCurl not support it?
- RCurl does support it, but the likely problem is that the version of libcurl you have installed does not support it. You can check what protocols your libcurl and hence RCurl supports via the command
curlVersion. If scp and sftp are not there, reinstall libcurl but with support using libssh2. You will need to have the libssh2 development libraries and headers installed before installing libcurl. On some OSes, you will need to rebuild RCurl from source.- I am trying to download a file via FTP, but it takes a very long time. Any suggestions?
- We saw this in a posting to R-help by Zack Holden. There the issue was passive mode. When using R's own download.file() function, an error was raised. When using RCurl's getURL(), the file was correctly downloaded, but it took a long time. There was about 3 minutes of delay. This can be seen with
getURL('ftp://ftp.wcc.nrcs.usda.gov/data/snow/snow_course/table/history/idaho/13e19.txt', verbose = TRUE)One can see the request just waits for a long period of time and then eventually the contents of the file are displayed in the R session.The fix for this is to avoid extended passive mode and use the regular passive mode. This is controlled via the ftp.use.epsv option in calls to curlPerform() and we set this to FALSE so that PASV is used rather than EPSV.
getURL('ftp://ftp.wcc.nrcs.usda.gov/data/snow/snow_course/table/history/idaho/13e19.txt', ftp.use.epsv = FALSE)- I want to download all the files in an FTP directory. How do I do it?
- First, we can get a list of all the file names with
url = 'ftp://ftp.wcc.nrcs.usda.gov/data/snow/snow_course/table/history/idaho/' filenames = getURL(url, ftp.use.epsv = FALSE, ftplistonly = TRUE) filenames = paste(url, strsplit(filenames, "\n")[[1]], sep = "")
Now we can download each of these in turn. It is advisable to create a curl handle just once and to set any options before downloading any of the files.con = getCurlHandle( ftp.use.epsv = FALSE) sapply(filenames, getURL, curl = con)
- When I try to interact with a URL via https, I get an error of the form
Error in curlPerform(url = url, headerfunction = header$update, curl = curl, : SSL certificate problem, verify that the CA cert is OK. Details: error:14090086:SSL routines:SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
What can I do?Information about this came from http://ademar.name/blog/2006/04/curl-ssl-certificate-problem-v.html
Basically, the remote server is sending us a certificate to say it is who it says it is. However, we have to trust that certificate. We do this by providing information about a collection of trusted signing authorites, e.g. Verisign, Entrust, Thawte We can use the certificates from these agents from the Netscape collection, available via http://curl.netmirror.org/docs/caextract.html, but you can find other collections. We download this file or its equivalent. Next we need to tell libcurl to use that file and where to find it. We do this with the cainfo option.
x = getURLContent("https://www.google.com", cainfo = "/Users/duncan/cacert.pem")Note that we cannot use a ~ in the file path; we have to expand it ourselves.x = getURLContent("https://www.google.com", cainfo = path.expand("~/cacert.pem"))To avoid having to specify the location of the bundle in each call, you can place the file in a place that libcurl looks. This is usually the file /usr/local/share/curl/curl-ca-bundle.crt If you have write permission for this directory, you can place the files. (The file must be present before libcurl is configured and compiled.)
On some versions of UNIX, the certificates will also be found in /usr/share/ssl/certs/ca-bundle.crt
If you don't have a certificate from an appropriate signing agent, you can suppress verifying the certificate with the ssl.verifypeer option:
x = getURLContent("https://www.google.com", ssl.verifypeer = FALSE)This does risk a 'man in the middle' attack.- I'm trying to POST a request but this fails. Does it have anything to do with the %'s in my parameter values?
- (Taken from a query from Olivier Merle. )
x = postForm("http://www.fas.usda.gov/psdonline/psdResult.aspx", style = "post", .params = list(visited="1", lstGroup = "all", lstCommodity="2631000", lstAttribute="88", lstCountry="**", lstDate="2011", lstColumn="Year", lstOrder="Commodity%2FAttribute%2FCountry"))This fails with a simple message from the server that the "Custom Query results" cannot be displayed. Note the lstOrder parameter. It has %2F in two places. This is the "percent encoding" for the character /. postForm does the percent encoding on the inputs and so ends up encoding %2F, ending up with "%252F" in place of each "%2F".So, don't pass percent encoded strings, but rather use human-readable versions, e.g. lstOrder="Commodity/Attribute/Country" and leave postForm to handle the encoding. Alternatively, you can tell postForm not to percent-encode specific parameters by passing them As-Is, e.g.
lstOrder = I("Commodity%2FAttribute%2FCountry")- Okay, how do I perform a PUT operation in RCurl?
- Well here is the lowest-level version:
val = rawToChar(textToSend) curlPerform(url = "http://localhost:9200/a/b/axyz", customrequest = "PUT", readfunction = val, infilesize = length(val), upload = TRUE)textToSend is the content we want to send. We convert it to raw. Then we specify the URL, that we want a PUT request, and we specify the raw object as the value for readfunction and also the number of elements in val as the value of infilesize. The last option - upload - is vital. What happens here is that RCurl reads bytes from val as it needs to send them to the server.A slightly shorter way to do this is
httpPUT("http://localhost:9200/a/b/axyz", readfunction = val, infilesize = length(val), upload = TRUE)From version 1.91-0, you can simply usehttpPUT(url, textToSend)
and the function will fill in the other curl options- When using authentication in an HTTP request, libcurl makes multiple requests. How can we make this more efficient?
- Basically, when we specify a username and password (e.g. via
userpwd) libcurl doesn't know which authentication mechanism to use. So it tries several in order until one is successful. So it is best to specify the authentication mechanism explicitly viahttpauth. Specify one of the values CURLAUTH_ - I have to specify followlocation = TRUE for all my requests. Why can't RCurl just do this for me.
Duncan Temple Lang <duncan@wald.ucdavis.edu> Last modified: Tue May 29 06:57:38 PDT 2012